第1章 C语言概述
1. C语言出现的历史背景- C语言是国际上广泛流行的高级语言。
- C语言是在B语言的基础上发展起来的。
- B (BCPL)语言是1970年由美国贝尔实验室设计的, 并用于编写了第一个UNIX操作系统,在PDP 7上实现。优点:精练,接近硬件,缺点:过于简单,数据无类型。
- 1973年贝尔实验室的D.M.Ritchie 在B语言的基础上设计出了C语言,对B取长补短,并用之改写了原来用汇编编写的UNIX,(即UNIX第5版),但仅在贝尔实验室使用。
- 1975年UNIX第6版发布,C优点突出引起关注。
- 1977年出现了《可移植C语言编译程序》 ,推动了UNIX在各种机器上实现 ,C语言也得到推广,其发展相辅相成。
- 1978年影响深远的名著《The C Programming Language》由 Brian W.Kernighan和Dennis M.Ritchie 合著,被称为标准C。
- 之后,C语言先后移植到大、中、小、微型计算机上,已独立于UNIX和PDP,风靡世界,成为最广泛的几种计算机语言之一。
- 1983年,美国国家标准化协会(ANSI)根据C语言各种版本对C的发展和扩充,制定了新的标准ANSI C ,比标准C有了很大的发展。
- 1988年K & R按照 ANSI C修改了他们的《The C Programming Language》。
- 1987年,ANSI公布了新标准——87 ANSI C。
- 1990年,国际标准化组织接受了87 ANSI C为ISO C 的标准(ISO9899—1990)。
- 1994年,ISO又修订了C语言标准。
- 目前流行的C语言编译系统大多是以ANSI C为基础进行开发的
2. C语言的特点
- (1)语言简洁、紧凑,使用方便、灵活。 32个关键字、9种控制语句,程序形式自由。
- (2)运算符丰富。34种运算符 。
- (3)数据类型丰富,具有现代语言的各种数据结构。
- (4)具有结构化的控制语句 ,是完全模块化和结构化的语言。
- (5)语法限制不太严格,程序设计自由度大。
- (6)允许直接访问物理地址,能进行位操作,能实现汇编语言的大部分功能,可直接对硬件进行操作。兼有高级和低级语言的特点 。
- (7)目标代码质量高,程序执行效率高。只比汇编程序生成的目标代码效率低10%-20%。
- (8)程序可移植性好(与汇编语言比)。基本上不做修改就能用于各种型号的计算机和各种操作系统。
- 问题:既然有了面向对象的C++语言,为什么还要学习C语言?
- 解释1:C++是由于开发大型应用软件的需要而产生的,并不是所有的人都要去编写大型软件。
- 解释2:面向对象的基础是面向过程。C++是面向对象的语言,C是面向过程的,学起来比C语言困难得多,所以不太适合程序设计的初学者。
3. 运行C程序的步骤

第2章. 程序的灵魂——算法
1. 计算机算法可分为两大类别:
- 数值运算算法:求数值解,例如求方程的根、求函数的定积分等。
- 非数值运算:包括的面十分广泛,最常见的是用于事务管理领域,例如图书检索、人事管理、行车调度管理等。
2. 结构化程序设计
- 一个结构化程序 就是用高级语言表示的结构化算法。用三种基本结构组成的程序必然是结构化的程序,这种程序便于编写、便于阅读、便于修改和维护。
- 结构化程序设计强调程序设计风格和程序结构的规范化,提倡清晰的结构。
- 结构化程序设计方法的基本思路是:把一个复杂问题的求解过程 分阶段进行,每个阶段处理的问题都控制在人们容易理解和处理的范围内。
- 采取以下方法来保证得到结构化的程序:
- 自顶向下;
- 逐步细化;
- 模块化设计;
- 结构化编码。
第3章 数据类型、运算符、表达式
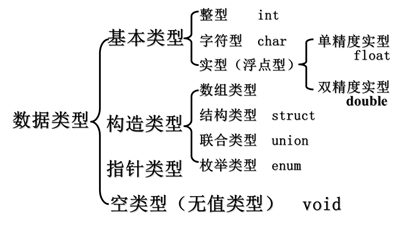
- C中的数据类型
- 常量与符号常量
- 常量区分为不同的类型:
- 整型 100,125,-100,0
- 实型 3.14 , 0.125,-3.789
- 字符型 'a', 'b','2'
- 字符串 'a', 'ab','1232'
3. 整型常量表示方法
- 整型常量即整常数。在C语言中,整常数可用以下三种形式表示:
- (1)十进制整数。
如:123, -456.4。
- (2)八进制整数。以0头的数是八进制数。
如:0123表示八进制数123,等于十进制数83,-011表示八进制数-11,即十进制数-9。
- (3)十六进制整数。以0x开头的数是16进制数。
如:0x123,代表16进制数123,等于十进制数 291。 -0x12等于十进制数-10。
-

(1)算术运算符 (+ - * / %)
(2)关系运算符 (><==>=<=!=)
(3)逻辑运算符 (!&&||)
(4)位运算符 (<< >> ~ |∧&)
(5)赋值运算符 (=及其扩展赋值运算符)
(6)条件运算符 (?:)
(7)逗号运算符 (,)
(8)指针运算符 (*和&)
(9)求字节数运算符(sizeof)
(10)强制类型转换运算符( (类型) )
(11)分量运算符(.->)
(12)下标运算符([ ])
(13)其他 (如函数调用运算符())
第八章 函数
1. 静态存储方式与动态存储方式
所谓静态存储方式是指在程序运行期间由系统分配固定的存储空间的方式。而动态存储方式则是在程序运行期间根据需要进行动态的分配存储空间的方式。这个存储空间可以分为三部分:
- 程序区
- 静态存储区
- 动态存储区
2.变量的声明与定义
对变量而言,声明与定义的关系稍微复杂一些。在声明部分出现的变量有两种情况:一种是需要建立存储空间的(如:int a; ),另一种是不需要建立存储空间的(如:extern a;)。前者称为"定义性声明"(defining declaration) ,或简称定义(definition)。 后者称为"引用性声明"(referencing declaration)。广义地说,声明包括定义,但并非所有的声明都是定义。对"int a;" 而言,它既是声明,又是定义。而对"extern a;" 而言,它是声明而不是定义。
一般为了叙述方便,把建立存储空间的声明称定义,而把不需要建立存储空间的声明称为声明。显然这里指的声明是狭义的,即非定义性声明。例如:
(1) 从作用域角度分,有局部变量和全局变量。它们采用的存储类别如下:
局部变量
|静态局部变量(离开函数,值仍保留)
|寄存器变量(离开函数,值就消失)
|(形式参数可以定义为自动变量或寄存器变量)
全局变量
|外部变量(即非静态的外部变量,允许其他文件引用)
(2) 从变量存在的时间(生存期)来区分,有动态存储和静态存储两种类型。静态存储是程序整个运行时间都存在,而动态存储则是在调用函数时临时分配单元。
|自动变量(本函数内有效)
|寄存器变量(本函数内有效)
静态存储
|静态外部变量(本文件内有效)
|外部变量(其他文件可引用)
(3) 从变量值存放的位置来区分,可分为:
内存中静态存储区
|静态局部变量
|静态外部变量(函数外部静态变量)
|外部变量(可为其他文件引用)
内存中动态存储区:
自动变量和形式参数
CPU中的寄存器:
寄存器变量
(4) 关于作用域和生存期的概念。从前面叙述可以知道,对一个变量的性质可以从两个方面分析,一是变量的作用域,一是变量值存在时间的长短,即生存期。前者是从空间的角度,后者是从时间的角度。二者有联系但不是同一回事。
(5) static对局部变量和全局变量的作用不同。对局部变量来说,它使变量由动态存储方式改变为静态存储方式。而对全局变量来说,它使变量局部化(局部于本文件),但仍为静态存储方式。从作用域角度看,凡有static声明的,其作用域都是局限的,或者是局限于本函数内(静态局部变量),或者局限于本文件内(静态外部变量)。
第十章 指针
1. 多维数组
int a[3][4]={
{1,3,5,7},{9,11,13,15},{17,19,21,23}};| 表 示 形 式 | 含义 | 地 址 |
| a | 二维数组名,指向一维数组a[0],即0行首地址 | 2000 |
| a[0],*(a+0),*a | 0行0列元素地址 | 2000 |
| a+1,&a[1] | 1行首地址 | 2008 |
| a[1],*(a+1) | 1行0列元素a[1][0]的地址 | 2008 |
| a[1]+2, *(a+1)+2, &a[1][2] | 1行2列元素a[1][2] 的地址 | 2012 |
| *(a[1]+2), *(*(a+1)+2), a[1][2] | 1行2列元素a[1][2]的值 | 元素值为13 |
2. 字符数组和字符指针变量二者之间的区别:
(1) 字符数组由若干个元素组成,每个元素中放一个字符,而字符指针变量中存放的是地址(字符串第1个字符的地址),决不是将字符串放到字符指针变量中。
(2)赋值方式。对字符数组只能对各个元素赋值,不能用以下办法对字符数组赋值。
char str[14];
str=″I love China!″;
而对字符指针变量,可以采用下面方法赋值:
char*a;
a=″I love China!″;
(3)对字符指针变量赋初值:
char *a=″I love China!″;等价于
char*a;
a=″I love Chian!″;
而对数组的初始化:
char str[14]={″I love China!″};
不能等价于
char str[14];
str[ ]=″I love China!″;
(4) 定义了一个字符数组,在编译时为它分配内存单元,它有确定的地址。而定义一个字符指针变量时,给指针变量分配内存单元,在其中可以放一个字符变量的地址。
例如: char str[10];
scanf(″%s″,str);
第十三章 文件操作
1.文件处理
- C语言对文件的处理方法:
缓冲文件系统:系统自动地在内存区为每一个正在使用的文件开辟一个缓冲区。用缓冲文件系统进行的输入输出又称为高级磁盘输入输出。
非缓冲文件系统:系统不自动开辟确定大小的缓冲区,而由程序为每个文件设定缓冲区。用非缓冲文件系统进行的输入输出又称为低级输入输出系统。
说明:
在UNIX系统下,用缓冲文件系统来处理文本文件,用非缓冲文件系统来处理二进制文件。
ANSI C 标准只采用缓冲文件系统来处理文本文件和二进制文件。
C语言中对文件的读写都是用库函数来实现。
Turbo C在stdio.h文件中有以下的文件类型声明:
}FILE;
在缓冲文件系统中,每个被使用的文件都要在内存中开辟一
FILE类型的区,存放文件的有关信息。
FILE类型的数组:
FILE f[5];定义了一个结构体数组f,它有5个元素,可以用来存放5个文件的信息。
文件型指针变量:
FILE *fp;fp是一个指向FILE类型结构体的指针变量。可以使fp指向某一个文件的结构体变量,从而通过该结构体变量中的文件信息能够访问该文件。如果有n个文件,一般应设n个指针变量,使它们分别指向n个文件,以实现对文件的访问。
3.文件读写结构体
若有如下结构类型:
可以用fread和fwrite来进行数据的操作:
4.fread与fscanf
注意:
用fprintf和fscanf函数对磁盘文件读写,使用方便,容易理解,但由于在输入时要将ASCII码转换为二进制形式,在输出时又要将二进制形式转换成字符,花费时间比较多。因此,在内存与磁盘频繁交换数据的情况下,最好不用fprintf和fscanf函数,而用fread和fwrite函数。